Subtask 1.1 Read the Movies Data
To read the data in form of CSV/excel Format firstly you need to export the Pandas Library of python. Pandas Module in Python is basically used in data science for performing various Analyses.
To following code will tell you how to import Pandas in Jupyter Notebook:

Now, as the Panda Library is imported, We can read the data through the following code:
pd.read_csv(dataset location...)
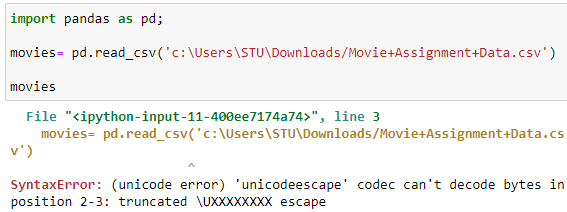
But the above picture shows us the error while executing the code.
What is the reason behind that and How it can be resolved?
If you compare the code by the syntax above, you can clearly make out that 'c:\Users\STU\Downloads/Movie+Assignment+Data.csv' is the location of the Dataset that we are providing. We have similarly executed the code like that shown in the syntax. Still, we face this error.
REASON: The compiler considers the location that you are passing as a simple string. So if you will the code is given below, your location will be considered as a Raw String. Therefore, resulting in the execution of the code.
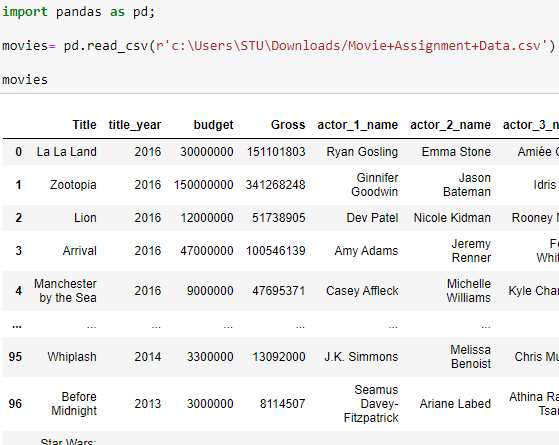
Also, you can use another method as:
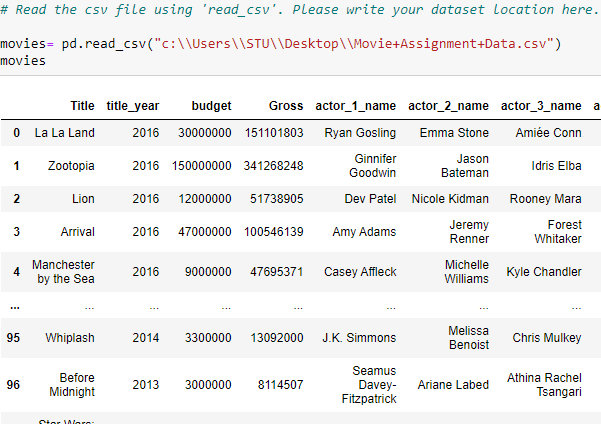
Subtask 1.2: Inspect the Dataframe
After reading the file through read_csv(). The very next step we are going to do is to check the data that we have.
Some basic Operations that we did to check data, is as follows:
1)To check the number of rows and columns in a Dataset we use the shape keyword. Basically, the keyword describes the shape of the data set in for of ( Rows, Columns).
movies.shape
2) To find the column-wise information of a Dataset we use the info keyword. Info Keyword in Pandas is used to find the information of the Dataset concerning the name of the column, Datatype it contains, along with describing the nullability.
movies.info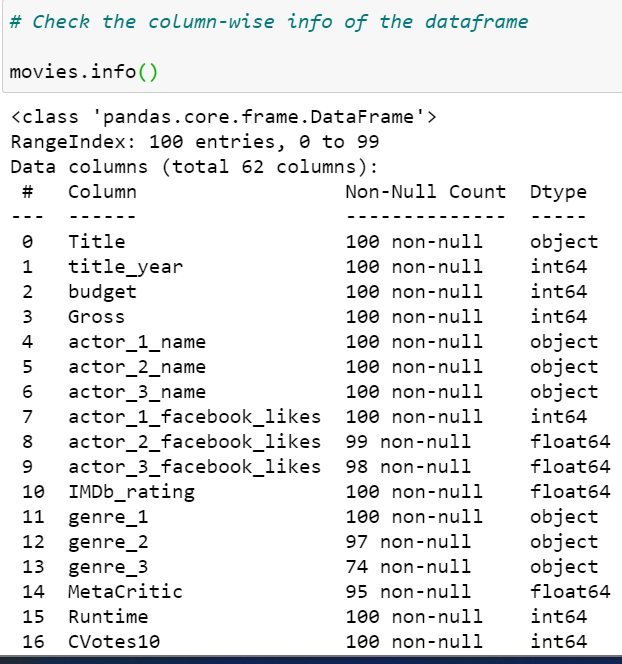
3) describe() function in Pandas can be used to find some statistical calculations on the numerical data in the dataset. Therefore, to find the summary of numeric columns in Dataset we can use describe().
movies.describe()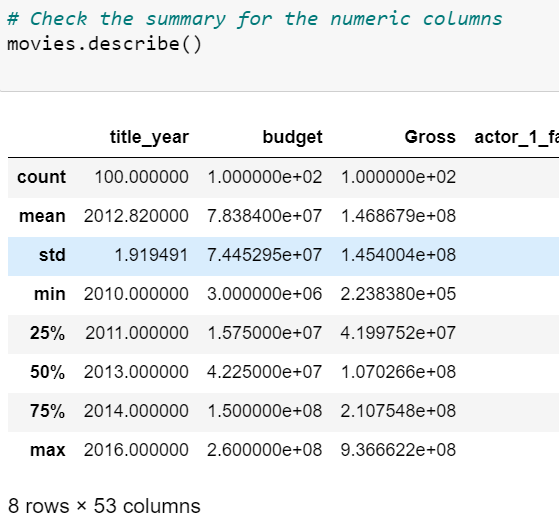
- Log in to post comments