Hadoop and Spark are popular Apache projects in the Big Data Ecosystem. A direct comparison between Hadoop and Spark is difficult because they do the same thing but are also non-overlapping in some areas, for example, Spark has no file management and therefor must rely on HDFS or some other solution. MapReduce is a startup system for several companies that began their journey in Big Data when Apache Hadoop appeared. This Framework has been the first fruit of the projects which is interested in the analysis of the distributed data in the sense of Big Data. One of the significant challenges for systems developed with this Framework is its high-latency, batch-mode response (Comparing Hadoop, MapReduce, Spark, Flink, and Storm - MetiStream). Some developers would complain that it is difficult to maintain MapReduce because of inherent inefficiencies in its design and in its code, even if MapReduce has been evolved over the last thirteen years (MapReduce and Spark - Cloudera VISION). On the other hand, Spark is more nimble and better suited for Big Data analytics. It can run on a variety of file systems and databases, Spark processes work 100 times faster than the same process on MapReduce.
| Hadoop MapReduce | Apache Spark | |
|---|---|---|
| Developed at | UC BerKeley | |
| Designed for | Batch processing | Real time and streaming processing |
| Written in | Java | Scala |
| Intermediate results | Stored in hard disk | Stored in memory |
| Programming Language support | Primarily Java, other languages like C, C++, Ruby, Groovy, Perl, and Python. | Scala, Java, Python, R, and SQL |
| Storage | Disk only | In-memory or on disk |
| OS support | Supports cross platform | Supports cross platform |
| Speed | Reads and writes from a disk which slows down the processing speed | Reads and writes from memory which makes processing speed very fast |
| Real time | MapReduce cannot succeed, because it has been dedicated to performing batch analysis on large amounts of data. | Spark can process real-time data, that means, data from realtime event streams at millions of events per second, sharing / viewing from social networks for example. It is dedicated to the treatment in real-time |
| Streaming | Can only process data in batch mode. | Spark makes it possible to process data which are fixed at a time T. Thanks for the Spark Streaming module, it is possible to process data streams which arrive continuously, and thus to process these data as they arrive. |
| Difficulty | The developers In MapReduce are needed to hand code each and every operation, which makes MapReduce very difficult to program. | With Resilient Distributed Datasets (RDDs) Spark is easy to program. |
Apache Spark saw tremendous growth compared to Hadoop, Spark’s growth comes not only from a huge increase in the number of contributors, devellopers and users but also from increases in usage across a variety of organizations and functional roles. Apache spark is one of the most active Big Data projects (Databricks, 2015), but it is wiser to compare Hadoop MapReduce to Spark, because they’re more comparable. The following section provides a comparison between them, we will cover a general differences.
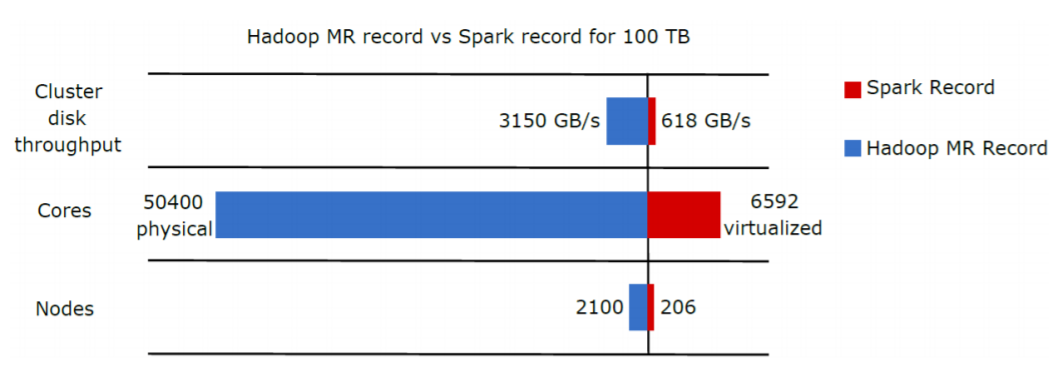
Spark can be used to analyze data that is too large. In addition, like Hadoop, Spark can work on unstructured, semistructured or structured data. In Daytona Graysort Challenge (Daytona 100TB) on 2014, Spark largely outpaced MapReduce, with a team from Databricks including Spark committers, Reynold Xin, Xiangrui Meng, and Matei Zaharia. Spark won a tie with the Themis team from UCSD, and set a new world record in sorting. With 206 EC2 i2.8xlarge machines, Spark reaches a record of 23 minutes to sort 100TB of data. On the other hand, the record established by Hadoop MapReduce cluster was 72 minutes, with 2100 nodes to sort the same quantity (100TB). This means that Apache Spark is 3 times faster than Hadoop MapReduce, and it uses 10 times less machines. All the sorting took place on disk (HDFS), without using Spark’s in-memory cache (Spark wins Daytona Gray Sort 100TB Benchmark | Apache Spark) (Databricks)(Sort Benchmark)
The results correspond to Daytona Graysort Challenge for Cluster disk throughput, Cores and Nodes
The results correspond to Daytona Graysort Challenge for Sort rate/node, Sort rate and Network

Hadoop has a powerful distributed storage file (HDFS), with performances and features that are available for Big Data processing systems such as Hadoop MapReduce and Apache Spark. Hadoop MapReduce is a platform built for batch processing. It was very famous and very usable by multiple companies in several areas, because Hadoop MapReduce was the first technology that analyze mass distributed data. On the other hand, Apache Spark is the new brightest platform on the Big Data technology, it has better performances. The Spark is very profitable thanks to the data processing in memory, it is compatible with all of the data sources and file formats of Hadoop, also it has several APIs. Apache Spark even includes graph processing and machine-learning capabilities. Although some companies feel compelled to choose between Hadoop and Spark, the fact that isn't a direct fight.
They are complementary technologies that work in tandem in some cases, or separately in other cases, depending on the data or the desired results. The truth is that Spark and Hadoop have a dependent relationship with each other. Hadoop provides options that Spark doesn't possess like HDFS, and Spark provides real-time, in-memory processing. The perfect scenario of Big Data, is that Hadoop and Spark work together on the same team.
- Log in to post comments