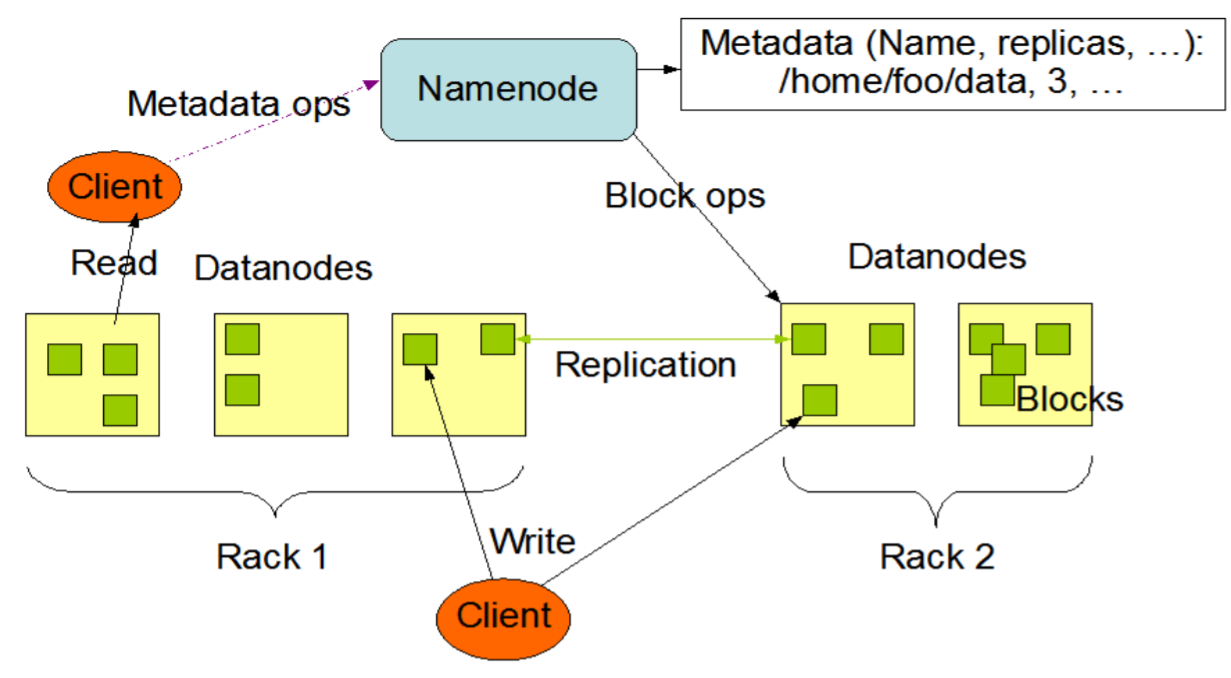
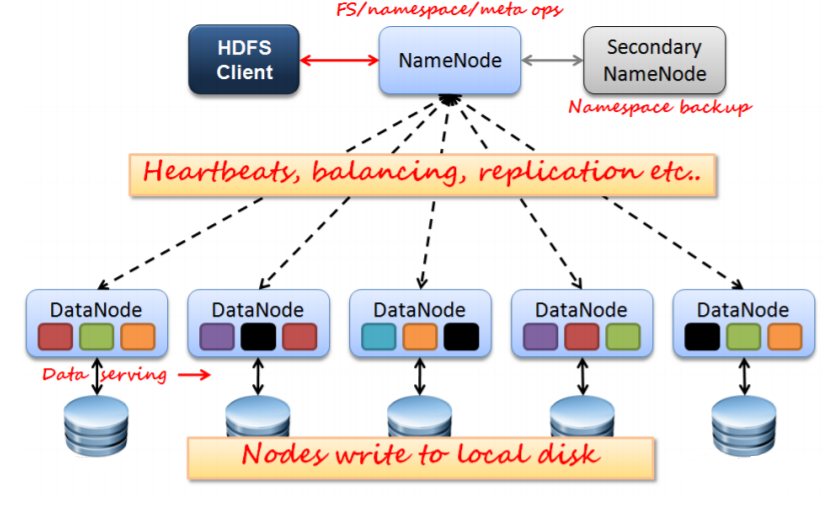
The structure of HDFS is a master/slave model. The HDFS cluster will have one single name node, the master server that organize the namespace and control the files that are accessed by clients. Then under the name node, there are several data nodes that manage storage attached to the nodes. They store and retrieve blocks as the name node or the clients requested and send back the set of blocks that carry those information.
The blocks are stored internally in the name node and they are much larger than a normal block in a disk. The default for the block is 64MB and files are broken into block-sized chunks to be stored. There are several benefits of having a block structure for the distributed system. First, since a file can be larger than the disk in the network, the file can be divided into several blocks and to be stored on different disks. This way, the file can actually be processed in parallel. In addition, for fault tolerance and recovery, block structure is easily replicated from another disk and bring the process back to normal.
Namenode
The namenode is the commodity hardware that contains the GNU/Linux operating system and the namenode software. It is a software that can be run on commodity hardware. The system having the namenode acts as the master server and it does the following tasks −
Manages the file system namespace.
Regulates client’s access to files.
It also executes file system operations such as renaming, closing, and opening files and directories.
Datanode
The datanode is a commodity hardware having the GNU/Linux operating system and datanode software. For every node (Commodity hardware/System) in a cluster, there will be a datanode. These nodes manage the data storage of their system.
Datanodes perform read-write operations on the file systems, as per client request.
They also perform operations such as block creation, deletion, and replication according to the instructions of the namenode.
Block
Generally the user data is stored in the files of HDFS. The file in a file system will be divided into one or more segments and/or stored in individual data nodes. These file segments are called as blocks. In other words, the minimum amount of data that HDFS can read or write is called a Block. The default block size is 64MB, but it can be increased as per the need to change in HDFS configuration.
Since HDFS is built using the Java language, any machine that supports Java can run the name node or the data node software. There exists a variety of other interfaces that are compatible using HDFS by different methods, this include Thrift, C, FUSE, WebDAV, HTTP and FTP. Usually, the other file system interfaces need additional integration in order to access HDFS. For example, for some non-Java applications that have Thrift bindings, they use the Thrift API in their implementation by accessing the Thrift service and ease the interaction to Hadoop.
HDFS interacts with other components of Apache Hadoop to distribute files and data as requested.
- Log in to post comments