Up to now, we have seen the INSERT IGNORE and REPLACE which does the operation of inserting and replacing values without any compromise on other data insertion.
But when REPLACE finds an insertion error it will delete the row and does the operation of adding a new record. INSERT ON DUPLICATE KEY UPDATE does not delete duplicate row instead when it finds out the error of unique or primary key error it simply updates onto the existing row.
Syntax
INSERT INTO Table(ColumnNames)
VALUES(Values)
ON DUPLICATE KEY UPDATE
columnname = expression; Example
We will be using this table to do this operation:
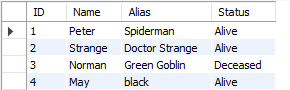
INSERT INTO upsert_example(ID, Name, Alias, Status)
VALUES (4,'May', 'black', 'Alive') ON DUPLICATE KEY UPDATE Status = 'Deceased', Alias = 'Aunt';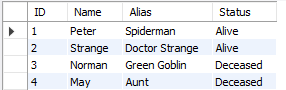
So here we can see that the exact column value is updated, unlike REPLACE which deletes the entire record and updates the new record in the name of Update.
- Log in to post comments