XPath is nothing but the XML path of WebElement. Absolute Xpath and Relative Xpath these two do the same job of tracking down the element but have some variations in their tracking.
Below are the difference between absolute xpath and relative xpath
| Point of Difference | Absolute Path | Relative Path |
|---|---|---|
| Starts with | Single Forward Slash. Select the element from the root <html> and cover the whole path to the element. It is also known as complete or Full Xpath. | Double Forward Slash. Expression can starts in the middle of the HTML DOM structure. |
| Speed | Faster. It identify the element very fast. | Slower compare to absolute. it will take more time in identifying the element as we specify the partial path not (exact path). |
| Failure Chances | More. It Changes Frequently, if there are any changes made in the path of the element then XPath gets failed. | Failure chance of well written relative path is very less |
| Example | /html/head/body/form/table /tbody/tr/th if any tag will be added before table the path will fail. | //table/tbody/tr/th Doesn't matter if anything added before table. |
Demo: Difference between Relative and Absolute Xpath
For demo purposes, we will be tracking XPath from our respective https://www.programsbuzz.com/
Absoute XPath
We will be taking absolute xpath for ask doubt which will go like this:
/html/body/div[2]/div[1]/div/header/div/div/div/div/div/div/div[2]/div/div/div/div[1]/div[2]/div/nav/div/div/ul/li[6]/a
Taken from the root of the element ask doubt is tracked via absolute XPath.
Relative XPath
//a[@href='/ask-doubt']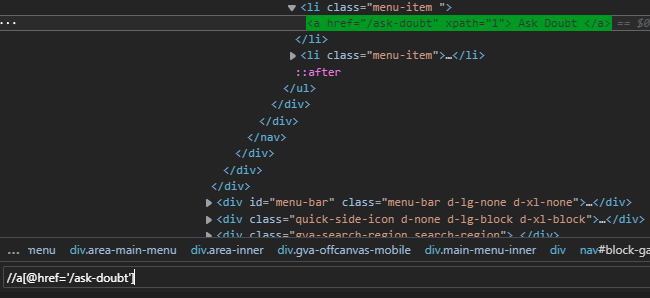
Taken from the exact tag element using the relative XPath method this when faced with any attribute change in the future is very much easy to deal with than absolute XPath.
So, to conclude Relative XPath are always preferred since it is not the complete path from the root element. Hence, there are less chance of becoming invalid.
- Log in to post comments