Cypress uncheck command is used to uncheck one or more checkboxes. It yields the same subject it was given from the previous command. Also, uncheck is an action command that follows all the rules of Actionability.
Syntax
.uncheck()
.uncheck(value)
.uncheck(values)
.uncheck(options)
.uncheck(value, options)
.uncheck(values, options)- value (string): single value of checkbox that should be unchecked
- value (array): multiple value of checkboxes that should be unchecked in array form
- options: You can use following options
- animationDistanceThreshold: The distance in pixels an element must exceed over time to be considered animating. Default Value: animationDistanceThreshold
- force: Forces the action, disables waiting for actionability. Default value: false
- log: Displays the command in the Command log. Default value: true
- scrollBehavior: Viewport position to where an element should be scrolled before executing the command. Default value: scrollBehavior
- timeout: Time to wait for .uncheck() to resolve before timing out. Default value: defaultCommandTimeout
- waitForAnimations: Whether to wait for elements to finish animating before executing the command.. Default value: waitForAnimations
Rules
- uncheck() requires being chained off a command that yields DOM element(s).
- uncheck() requires the element to have type checkbox .
- uncheck() will automatically wait for the element to reach an actionable state.
- uncheck() will automatically retry until all chained assertions have passed.
- uncheck() can time out waiting for the element to reach an actionable state.
- uncheck() can time out waiting for assertions you've added to pass.
Examples
Demo Link: http://autopract.com/selenium/form5/
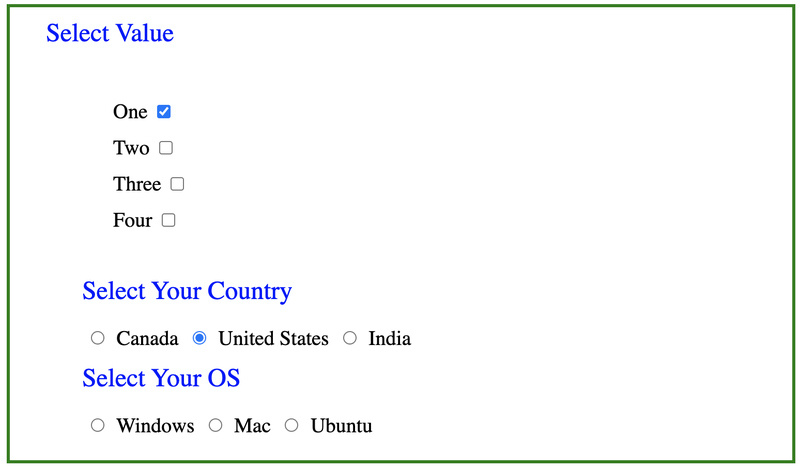
1. Uncheck Single Checkbox By Selector
it.only('uncheck', () => {
cy.visit('http://autopract.com/selenium/form5/')
// select all checkboxes
cy.get("[type='checkbox']").check()
// uncheck single checkbox with value one
cy.get("input[value='one']").uncheck()
}2. Uncheck Single Checkbox By Value
cy.get("[type='checkbox']").uncheck('one')3. Uncheck Multiple Checkboxes By Value
cy.get("[type='checkbox']").uncheck(['one', 'two'])4. Uncheck All Checkboxes
cy.get(':checkbox').uncheck()- Log in to post comments