The k-means++ algorithm addresses the second of these obstacles by specifying a procedure to initialize the cluster centers before proceeding with the standard k-means optimization iterations. With the k-means++ initialization, the algorithm is guaranteed to find a solution that is O(log k) competitive to the optimal k-means solution. Choosing centers in this way is both fast and simple, and it already achieves guarantees that k-means cannot. We propose using this technique to seed the initial centers for k-means, leading to a combined algorithm we call k-means++. To complement our theoretical bounds, we also provide experiments to show that k-means++ generally outperforms k-means in terms of both accuracy and speed, often by a substantial margin.
A major drawback of K Means is, that we need to determine the optimal values of K, and this is a very difficult job. Prior to solving the problem, it is difficult to know which value of K would do best for our particular problem. To overcome this difficult problem, we use the K+ Means algorithm, which incorporates a method to calculate a good value of K for our problems. K+ Means algorithm builds onto K Means algorithm, and is an enhancement to it. K+ Means is also great at detecting outliers, and forming new clusters for them. Therefore, K+ Means is not sensitive to outliers, unlike the K Means algorithm. we obtain an algorithm that is Θ(logk)-competitive with the optimal clustering by augmenting k-means with a very simple with randomized seeding technique.
The k-means++ algorithm We propose a specific way of choosing centers for the k-means algorithm. In particular, let D(x) denote the shortest distance from a data point to the closest center we have already chosen. Then, we define the following algorithm, which we call k-means++. K-means++ is the algorithm which is used to overcome the drawback posed by the k-means algorithm. This algorithm guarantees a more intelligent introduction of the centroids and improves the nature of the clustering. Leaving the initialization of the mean points the k-means++ algorithm is more or less the same as the conventional k-means algorithm.
We have to select a random first centroid point from the given dataset. For every instance say 'i' in the dataset calculate the distance say 'x' from 'i' to the closest, previously chosen centroid. Centroid selected from the dataset with the end goal that the likelihood of picking a point as centroid is corresponding to the distance from the closest, recently picked centroid. Repeated until you get k mean points.
SIMPLE STEPS
STEP 1: Find K clusters using the K-Means algorithm
STEP 2: For each of the clusters, calculate MIN, AVG and MAX intra cluster dissimilarity
STEP 3: If, for any cluster, AVG value is greater than others, then MIN and MAX values are checked. If the MAX value is higher too, we assign the corresponding data point as a new cluster and go back to step 1, with K+1 clusters.
STEP 4: Repeat STEPS 1 to 3 until no new clusters are formed.
ALGORITHM
- Choose an initial center c1 uniformly at random from S.
- For each data element x in S calculate the minimum squared distance between x and the centroids that have already been defined. Thus if centroids c1 ,…, cm have already been chosen define d(x) = (d)2(x, cj) where j = that h, 1 ≤ h ≤ m, for which (d)2(x, ch) has the minimum value.
- Choose the next center ci , selecting ci = x` ∈ S with probability
- Choose one of the data elements in S − {c1 ,…, cm} at random as centroid cm+1 where the probability of any data element x being chosen is proportional to d(x). Thus the probability that x is chosen is equal to d(x)/ d(z).
- Repeat Step 2 until k centroids have been chosen
K-means++ Algorithm Example:
from pandas import DataFrame
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
Data = {'x': [15,94,45,27,33,63,31,20,35,34,67,44,57,43,80,57,59,52,85,47,49,48,35,93,44,45,38,43,71,46,33,67,98,11,34,91],
'y': [80,51,53,70,59,74,73,57,69,70,51,32,47,40,54,36,30,58,59,50,25,20,15,12,20,5,23,77,81,7,45,21,97,94,33,88]
}
df = DataFrame(Data,columns=['x','y'])
kmeans = KMeans(n_clusters=7, init='k-means++').fit(df)
centroids = kmeans.cluster_centers_
print(centroids)
plt.scatter(df['x'], df['y'], c= kmeans.labels_.astype(float), s=70, alpha=1)
plt.scatter(centroids[:, 0], centroids[:, 1], c='red', s=70)
plt.show()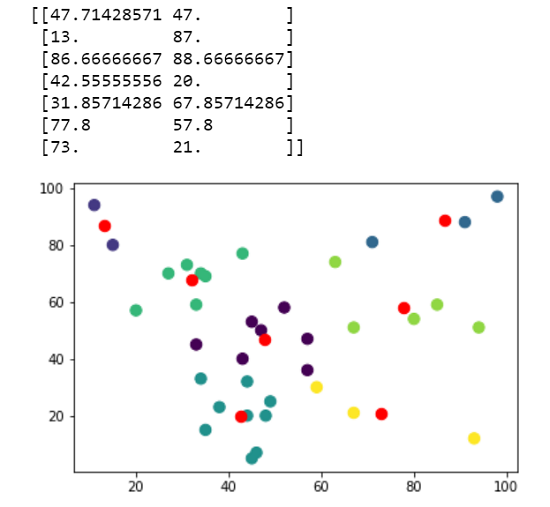
- Log in to post comments