Typically when you think of a “computer” you think about one machine sitting on your desk at home or at work. This machine works perfectly well for watching movies or working with spreadsheet software. However, as many users likely experience at some point, there are some things that your computer is not powerful enough to perform. One particularly challenging area is data processing. Single machines do not have enough power and resources to perform computations on huge amounts of information (or the user may not have time to wait for the computation to finish). A cluster, or group of machines, pools the resources of many machines together allowing us to use all the cumulative resources as if they were one. Now a group of machines alone is not powerful, you need a framework to coordinate work across them. Spark is a tool for just that, managing and coordinating the execution of tasks on data across a cluster of computers. The cluster of machines that Spark will leverage to execute tasks will be managed by a cluster manager like Spark’s Standalone cluster manager, YARN, or Mesos. We then submit Spark Applications to these cluster managers which will grant resources to our application so that we can complete our work.
Apache Spark has a well-defined and layered architecture where all the spark components and layers are loosely coupled and integrated with various extensions and libraries. Apache Spark Architecture is based on two main abstractions-
- Resilient Distributed Datasets (RDD)
- Directed Acyclic Graph (DAG)
Resilient Distributed Datasets (RDD)
RDD’s are collection of data items that are split into partitions and can be stored in-memory on workers nodes of the spark cluster. In terms of datasets, apache spark supports two types of RDD’s – Hadoop Datasets which are created from the files stored on HDFS and parallelized collections which are based on existing Scala collections. Spark RDD’s support two different types of operations – Transformations and Actions. An important property of RDDs is that they are immutable, thus transformations never return a single value. Instead, transformation functions simply read an RDD and generate a new RDD. On the other hand, the Action operation evaluates and produces a new value. When an Action function is applied on an RDD object, all the data processing requests are evaluated at that time and the resulting value is returned.
Directed Acyclic Graph (DAG)
Direct - Transformation is an action which transitions data partition state from A to B.
Acyclic -Transformation cannot return to the older partition
DAG is a sequence of computations performed on data where each node is an RDD partition and edge is a transformation on top of data. The DAG abstraction helps eliminate the Hadoop MapReduce multi0stage execution model and provides performance enhancements over Hadoop. Apache Spark follows a master/slave architecture with two main daemons and a cluster manager –
- Master Daemon – (Master/Driver Process)
- Worker Daemon –(Slave Process)
A spark cluster has a single Master and any number of Slaves/Workers. The driver and the executors run their individual Java processes and users can run them on the same horizontal spark cluster or on separate machines i.e. in a vertical spark cluster or in mixed machine configuration. For classic Hadoop platforms, it is true that handling complex assignments require developers to link together a series of MapReduce jobs and run them in a sequential manner. Here, each job has a high latency. The job output data between each step has to be saved in the HDFS before other processes can start. The advantage of having DAG and RDD is that they replace the disk IO with in-memory operations and support in-memory data sharing across DAGs, so that different jobs can be performed with the same data allowing complicated workflows.
Spark Driver – Master Node of a Spark Application
It is the central point and the entry point of the Spark Shell (Scala, Python, and R). The driver program runs the main () function of the application and is the place where he Spark Context and RDDs are created, and also where transformations and actions are performed. Spark Driver contains various components – DAGScheduler, TaskScheduler, BackendScheduler, and BlockManager responsible for the translation of spark user code into actual spark jobs executed on the cluster.
Spark Driver performs two main tasks: Converting user programs into tasks and planning the execution of tasks by executors. A detailed description of its tasks is as follows:
- The driver program that runs on the master node of the spark cluster schedules the job execution and negotiates with the cluster manager.
- It translates the RDD’s into the execution graph and splits the graph into multiple stages.
- Driver stores the metadata about all the Resilient Distributed Databases and their partitions.
- Cockpits of Jobs and Tasks Execution -Driver program converts a user application into smaller execution units known as tasks. Tasks are then executed by the executors i.e. the worker processes which run individual tasks.
- Driver exposes the information about the running spark application through a Web UI at port 4040.
Role of Executor in Spark Architecture
Executor is a distributed agent responsible for the execution of tasks. Every spark applications has its own executor process. Executors usually run for the entire lifetime of a Spark application and this phenomenon is known as “Static Allocation of Executors”. However, users can also opt for dynamic allocations of executors wherein they can add or remove spark executors dynamically to match with the overall workload.
- Executor performs all the data processing.
- Reads from and Writes data to external sources.
- Executor stores the computation results data in-memory, cache or on hard disk drives.
- Interacts with the storage systems.
Role of Cluster Manager in Spark Architecture
An external service responsible for acquiring resources on the spark cluster and allocating them to a spark job. There are 3 different types of cluster managers a Spark application can leverage for the allocation and deallocation of various physical resources such as memory for client spark jobs, CPU memory, etc. Hadoop YARN, Apache Mesos or the simple standalone spark cluster manager either of them can be launched on-premise or in the cloud for a spark application to run.
Choosing a cluster manager for any spark application depends on the goals of the application because all cluster managers provide different set of scheduling capabilities. To get started with apache spark, the standalone cluster manager is the easiest one to use when developing a new spark application.
Spark Applications
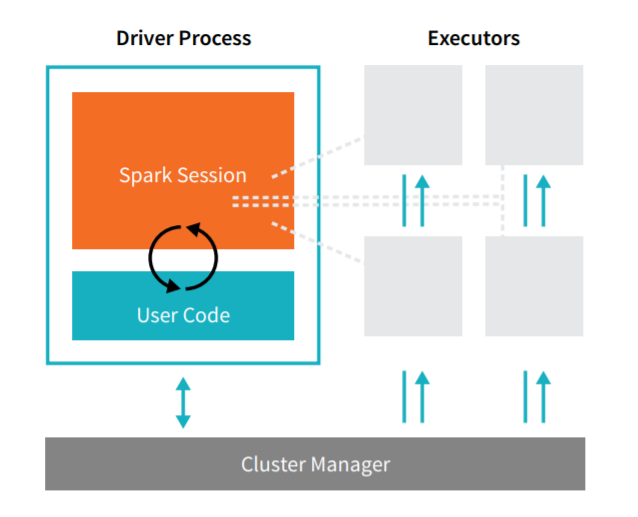
Spark Applications consist of a driver process and a set of executor processes. The driver process runs your main() function, sits on a node in the cluster, and is responsible for three things: maintaining information about the Spark Application; responding to a user’s program or input; and analyzing, distributing, and scheduling work across the executors (defined momentarily). The driver process is absolutely essential it’s the heart of a Spark Application and maintains all relevant information during the lifetime of the application. The executors are responsible for actually executing the work that the driver assigns them. This means, each executor is responsible for only two things: executing code assigned to it by the driver and reporting the state of the computation, on that executor, back to the driver node.
The cluster manager controls physical machines and allocates resources to Spark Applications. This can be one of several core cluster managers: Spark’s standalone cluster manager, YARN, or Mesos. This means that there can be multiple Spark Applications running on a cluster at the same time. We will talk more in depth about cluster managers in Part IV: Production Applications of this book. In the previous illustration we see on the left, our driver and on the right the four executors on the right. In this diagram, we removed the concept of cluster nodes. The user can specify how many executors should fall on each node through configurations.
Spark, in addition to its cluster mode, also has a local mode. The driver and executors are simply processes, this means that they can live on the same machine or different machines. In local mode, these both run (as threads) on your individual computer instead of a cluster. We wrote this book with local mode in mind, so everything should be runnable on a single machine.
As a short review of Spark Applications, the key points to understand at this point are that:
- Spark has some cluster manager that maintains an understanding of the resources available.
- The driver process is responsible for executing our driver program’s commands across the executors in order to complete our task. '
Now while our executors, for the most part, will always be running Spark code. Our driver can be “driven” from a number of different languages through Spark’s Language APIs.
- Log in to post comments